
Transforming Local Descriptor Hashes into a Powerful Tool for Detecting Known Harmful Content
Video is quickly becoming the primary mode of communication and expression online. And while video promises exciting new discoveries in the ways we can use online platforms to connect, its saturation across the web has created new challenges in ensuring users are kept both secure and safe. Platform trust and safety teams are in need of fast and efficient tools that can help them identify harmful content, including CSAM, and stop it from being reposted after its initial removal, and new developments in hash technology are quickly bringing these tools to fruition.
In this article, you’ll learn about how Videntifier has made major strides in solving video identification by fixing a major problem in hash technologies: Transforming local descriptor hashes into a powerful, lightweight solution.
Answered here:

Harmful content continues to circulate, even when platforms have seen it before
Video-sharing technology is a central function of almost every online platform available to users today, and is quickly becoming a, if not the, primary medium through which content is shared. Millions of videos are posted to platforms like Facebook, YouTube, and TikTok every day, with billions of users consuming and creating video content on a near-religious basis. While great strides in creativity and communication are thriving with video’s almost pervading presence on the web, video is also opening up new challenges for content moderators in their effort to maintain security and safety online.
Child Sexual Abuse Material (CSAM) is likely the most horrific example of how video is challenging the security and safety of users, and a core problem platforms face is the aggressive reuploading of known CSAM once it is taken down, leading to incessant cycles of revictimization. In a 2019 study done by the Canadian Centre for Child Protection, 30% of victims said they were at one point recognized by someone who had seen their abuse video. Statistics such as this indicate that recycled CSAM is able to stay live for far too long, subjecting those depicted in these videos to prolonged bouts of re-victimization.
While the biggest platforms have large moderation teams which can respond to complaints and do all they can to ensure these videos are taken down, these manual approaches can’t reach the scale needed to deal with the problem. Some platform trust and safety teams have implemented tools for automatically identifying previously-known CSAM, with hash-matching technologies using cryptographic and perceptual hashes being the two prime examples. But the plain truth of the matter is that most current technologies don’t provide the level of sophistication and power needed to help platforms accurately detect known CSAM, and one of the central reasons is this: offenders can easily evade detection using hash matching by deliberately modifying their videos.
A productive step in the right direction is to use innovative hashing approaches which radically improve the accuracy of video identification, specifically taking modifications into account.
The power of local descriptor hashes
New innovations in local descriptor hash technology have made exceptional strides in detecting known abuse videos, enabling platforms to quickly and efficiently identify known CSAM, potentially helping law enforcement to identify more offenders and victims. From our professional experience, the Videntifer team has seen local descriptor hashes work in conjunction with large CSAM databases like the National Center for Missing and Exploited Children’s (NCMEC) to provide an extremely effective solution for identifying harmful videos.
Local descriptor hashes offer capabilities that less sophisticated hash types lack, specifically the ability to identify video that is already in a database of known abuse content, but has been altered to avoid detection. Solving modifications such as cropping, bordering, embedding, and picture-in-picture are vital to putting a stop to recycled CSAM for good, and with local descriptors, platforms are finally able to do so.
All of this in mind, we’d like to take this opportunity to detail current methods of video detection, highlight their shortcomings, and explain how Videntifier’s local descriptor hashes have come a long way in their capabilities.
How are known abuse videos currently being detected by platforms?
As noted above, those platforms which use technology to automatically detect previously known videos generally use one or both of two types of hashing technology: Cryptographic (MD5, SHA-1) and perceptual hashes (PhotoDNA, TMK).
User-uploaded content is scanned and a hash - a unique digital fingerprint - is generated, then compared with the hashes in a database of known CSAM content like the one developed by the National Center for Missing and Exploited Children.
In the best case scenario, this approach allows a platform to automatically identify and remove bad content without a moderator having to view the traumatizing scenes depicted.
What problems do hash technologies face when identifying modified video?
Unfortunately, in practice, hash-matching using both cryptographic and perceptual hashes falls short in its ability to identify content that has been altered to avoid detection (i.e., grayscale, rotation, bordering, cropping, etc.).
This causes problems for platforms when attempting to determine whether the reported video is similar or identical to previously reported content, ultimately allowing reposted harmful content to avoid immediate detection and live online for a dangerously extended period of time.
The problem with cryptographic hashes
Cryptographic hashes, typically using the MD5 function, are only able to identify exact hash matches. This means that the slightest change to a file will change the hash value, and thus fail to identify the duplicate content.
In other words, this means that an abuser can change a single pixel of a soon-to-be reposted video to completely evade any and all attempts to re-identify the content and remove it. In fact, even when content is uploaded it is usually altered by platform algorithms which often strip out metadata and reencode the content, making cryptographic hashing an extremely ineffective approach to identifying known abuse content.
The problem with perceptual hashes
Perceptual hashes go farther in the identification of duplicated content, but still fall short in certain areas. Perceptual hash algorithms like those used by TMK can identify videos that have undergone minor modifications such as resizing, compression, and contrast changes, but cannot identify duplicates that have been cropped, watermarked, bordered, embedded with other media, or posted picture-in-picture, giving abusers the chance to avoid detection by simply adding one of these modifications.
The challenge of picture-in-picture
The picture-in-picture modification is a particularly difficult challenge for identifying duplicate videos, as the harmful ‘frames’ are seated within the ground of the encompassing primary frame. For example, when a CSAM video is flagged and taken down, the abuser might be able to avoid detection by reposting that same video playing in the fore- or background of a new video.

Why have local descriptors not generally been applied to videos?
Due to their high granularity, earlier approaches to local descriptor hashes have generally not been considered a viable solution for identifying video. The complexity with which previous approaches hash a video tended to lead to problems in search space, resulting in excessive computational costs and scalability problems that have left a bad taste in the mouths of hash tech software engineers.
For example, a 5 minute video processed at 5 frames a second is equivalent to about 1500 images, with each image containing somewhere between 50 and 300 descriptors. Other approaches to local descriptors are able to thoroughly hash the images for visually similar content, but the excessive strain in search space caused by local descriptor’s high-granularity has rendered these approaches far too slow to be used for trust and safety purposes. Put simply, the bandwidth for fast and efficient local descriptor hash-to-search functionality hasn’t been powerful enough to build an effective video identification solution, and it is because of this reason that local descriptors have not scaled well.
But here’s the good news: Our engineering team has found a way to resolve these issues.
How does Videntifier use local descriptors for fast and efficient video detection?
A two-pronged solution
Our remedy for the issues described above is essentially two-pronged in its approach. (1) Videntifier’s video identification tool is built on a highly sophisticated visual fingerprinting algorithm utilizing local descriptor hash technology. (2) When combined with Videntifier's patent-protected NV-Tree database index–powerful enough to serve thousands of user devices at the same time–what we have is a video identification tool that can effectively serve the needs of trust and safety teams.
Extracting descriptors efficiently
Videntifier’s descriptor extraction component processes the video frames and extracts visual descriptors as a collection of images. Extraction can be run on a multi-core server to fingerprint and manage large numbers of live streams or video/image catalogs. Our approach to local descriptors is resource-efficient and can be fine-tuned to extract the optimal number of frames, descriptors, and detail needed to perform effectively for a given use case.
Specifically, where traditional approaches to local descriptors spend time and resources hashing the entirety of a video by individual frame, our approach segments video files into scenes that contain visually similar content, allowing for a much leaner, much more efficient hash. Segmenting a video as such allows our technology to focus on vital match information only, which can then be used to search against any piece of content that has been reported.
Highly scalable database
Videntifier’s patent-protected and proprietary NV-Tree database structure is capable of storing many billions of descriptors, enabling identifying content against reference collections spanning millions of hours of video and billions of still images. The NV-Tree's most significant feature, however, is its search capacity which enables it to find similar descriptors in these huge reference collections in a matter of milliseconds. Together, these features make the NV-Tree database a critical component when it comes to making local-descriptor search work in practice. The NV-Tree can even be distributed across multiple servers at once in order to create near-limitless capacity.
What does our video solution mean for trust and safety teams?
Videntifier from a user perspective
From a user perspective, combining our approach to local descriptors and with the NV-Tree database’s unique scalable structure allows Videntifier to work with an ease comparable to a dictionary application. The client simply submits a set of descriptors into the database to see if they match any of their known reference content. If the match threshold passes a prespecified limit, it can be considered highly likely that the query video/image is the same as the one represented in the database, or that either one is part of the other.
This approach enables us to give trust and safety teams the ideal solution for matching known content and streamlining the identification of harmful material as it circulates across the web. Videntifier’s list of capabilities and user-friendly benefits includes but are not necessarily limited to:
1. Fast and accurate search
Trust and safety moderators can use Videntifier to quickly query and identify content against the entirety of their search database. Less robust tech is often tedious and time consuming attempting to execute content matches, but Videntifier’s local descriptors and NV-Tree technology have drastically reduced this massive computational load. When using Videntifier to query a match against the database, trust and safety teams can accurately identify whether a match exists in less than a second.
2. Protected user/client data
All queries are one-way encoded, meaning that the NV-Tree host has no recollection of the actual content signified in the inquiry. The server can only say that the two hashes being compared are either similarly encoded or not, and therefore has no access to the actual content.
The server can neither associate the query with a specific case/concept nor with a specific user without connection to specific metadata services. Furthermore, the descriptor encodes no specific objects in an image; instead, they roughly characterize shapes, usually at the borderline between different objects where the contrast is highest.
3. Multiple search query types
Because our approach to local descriptors segments videos according to scenes containing visually similar content, trust and safety teams have multiple match types at their disposal.

4. Exposure reduction
As illustrated above, our solution puts a wide variety of match types at the disposal of trust and safety teams, dramatically decreasing daily workload for the moderators who would otherwise need to manually review a great deal more content. What comes part and parcel with this drastic cut in workload is a significant reduction in the amount of CSAM a moderator is exposed to everyday.
After years of being exposed to this horrific content, moderators often suffer negative psychological side effects, such as PTSD. That in mind, if we can find solutions that save moderators from viewing this content, we should use them. Our approach to local descriptors gives platforms the option to reduce exposure, which, we hope, will help promote mental health in the moderation industry.
For example, let’s say a trailer-style video exists in the platform’s reference database, but a longer version of that same video has recently been reported. In such a case, all of the previously identified content can be blurred so the moderator only has to look at the new, unknown part of the video, saving the moderator from having to repeatedly expose themself to the known content as they review the new.
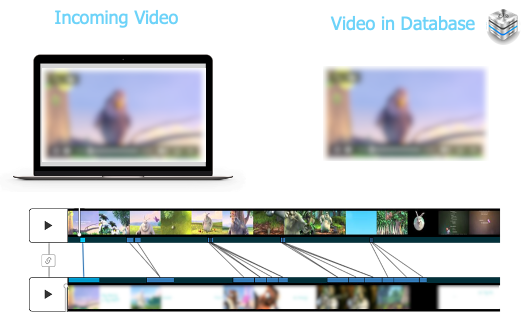
5. Identify content regardless of the type or extent of modification
Known CSAM can evade detection by applying both slight and extensive modifications to content. To provide an example, when a video is posted to social media but removed by moderators, it is often reposted later with applied picture-in-picture, borders, grayscale, and so on. Primitive tools unable to accurately detect video make it hard for platforms to detect these reposts, often living online for days, weeks, sometimes months, before being found and taken down.
We’ve said it quite a few times already, but we can’t stress it enough: The power and promise of local descriptor technology is its ability to identify videos despite significant and deliberate modification. Where crude video detection solutions built around cryptographic and perceptual hashes can only identify slight modifications (resizing, compression, contrast changes), our approach to local descriptors goes above and beyond by giving platforms a tool that effectively thwarts all attempts to pass reposted CSAM online undetected.
Videntifier local descriptors can ‘see through’ extensive modifications such as:
Bordering
Cropped with content overlays
Mirroring
Random rotation
Picture-in-picture
And more…
Working toward a permanent solution to CSAM videos
The world has yet to see a one-hundred-percent perfect solution to duplicate video identification, but these recent developments and insights into local descriptors have helped to create a tool that is highly effective in fulfilling moderators’ needs. Our engineering team has scraped local descriptors of their uneconomical qualities for an accurate video matching without wasted time or cost. With these developments, content moderators can now identify dramatically altered duplicate CSAM where cryptographic and perceptual hashes can’t, opening up a whole new level of efficacy in the fight against duplicate CSAM.
Comments